Before you read this section, if you are new to AI, I recommend a page “What is a model?” which gives you an overview of a machine learning model and how training works.
Functionalities in Stable Diffusion vs 3rd Party Modules
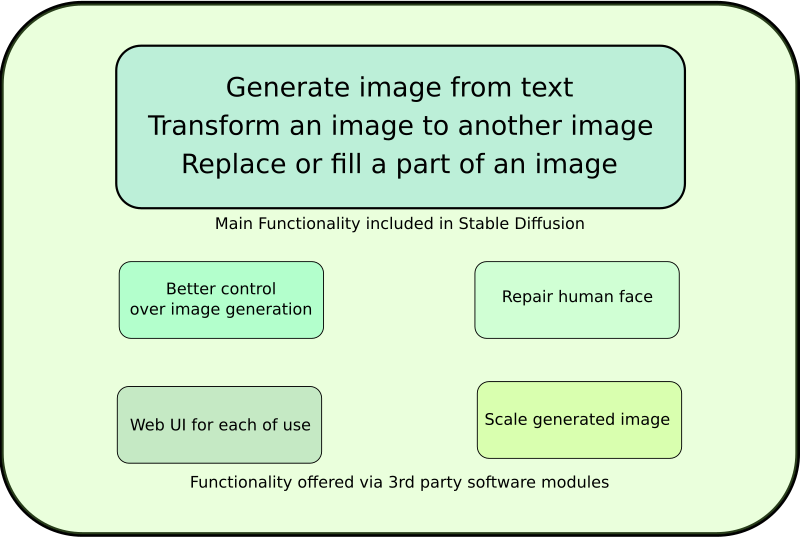
Stable Diffusion offers three primary functionalities essential for image generation:
- Text-to-Image Generation: Creating images from textual descriptions.
- Image-to-Image Transformation: Modifying an existing image into a new form.
- Inpainting: Replacing or filling parts of an image.
While these features are foundational for image generation, certain limitations are observed:
- Lack of Precise Shape Control: The ability to dictate specific image shapes is limited.
- Inconsistent Human Face Rendering: Faces in generated images may appear distorted.
- Limited Resolution: The default resolution is relatively low at 512×512 pixels.
- User Interface Complexity: The command-line interface (CLI) can be challenging for some users.
To overcome these challenges, various third-party software modules, some specifically designed for Stable Diffusion and others developed independently, can be integrated. Available modules include:
- Precise Control Over Image Generation: ControlNet allows for more detailed guidance in image creation.
- Human Face Repair: Tools like GFPGAN and CodeFormer specialize in enhancing facial features in images.
- User-Friendly Web Interface: Automatic1111 and ComfyUI offer more accessible web-based interfaces.
- Image Scaling: R-ESRGAN and ESRGAN enhance the resolution of generated images.
These enhancements address the core shortcomings of Stable Diffusion, enabling higher-quality, user-friendly image generation.
Components within Stable Diffusion
If you enter “A photo of a puppy” to Stable Diffusion, it can generate an image of a cute puppy like below. To lots of people, this may look like magic.
However, in order to help generate a better image, understanding at least high-level what happens in Stable Diffusion.
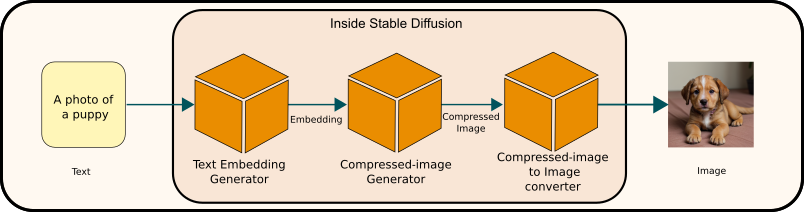
Upon delving into the ‘magic box’ of Stable Diffusion, you’ll encounter three models integral to its functionality:
- Text Embedding Generator: This component is fundamental in processing and interpreting input text data.
- Compressed-Image Generator: As the name I’ve chosen suggests, this model specializes in generating images in a compressed format.
- Compressed-Image to Image Converter: This final model converts compressed images into standard image formats.
Click on the links above to view the overview of each model. Note: ‘Compressed-Image Generator’ and ‘Compressed-Image to Image Converter’ are simplified terms I’ve used for clarity, not standard academic terms. Their conventional names will be introduced on each corresponding page.