
What is ControlNet and why is it needed?
Welcome to the first in our series of tutorials on ControlNet. This tutorial aims to explain what ControlNet is and its necessity. Understanding its core concept is crucial for both installation and effective usage. ControlNet is a software add-on to provide visual cues to Stable Diffusion, guiding it to produce images that closely match your envisioned target. To illustrate its functionality, let’s delve into a specific example: generating a picture of five oranges arranged in a particular manner.

To generate an image of five oranges, you might start with the following generation parameters:
A photo of five oranges,
highly detailed, photorealistic, 4k, uhd
Negative prompt: low quality
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1026719745, Size: 512x512, Model hash: 76be5be1b2, Model: epicrealism_pureEvolutionV5, VAE hash: f921fb3f29, VAE: vae-ft-mse-840000-ema-pruned.ckptBut most likely you get something like these:

Considering the initial results, you might then decide to enhance the output by updating the positive prompt with more descriptive details:
A photo of five oranges arranged in the pattern of the number 5 on a die,
highly detailed, photorealistic, 4k, uhd
Negative prompt: low quality
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3700252527, Size: 512x512, Model hash: 76be5be1b2, Model: epicrealism_pureEvolutionV5, VAE hash: f921fb3f29, VAE: vae-ft-mse-840000-ema-pruned.ckpt
Despite your efforts, the results are not meeting your expectations. This discrepancy often arises because accurately conveying a complete image through words alone is a significant challenge, and Stable Diffusion still has ample room for improvement in interpreting prompts accurately. What if we provide more specific cues, particularly visual ones? This is precisely the aim of ControlNet. For instance, a text prompt like ‘An elephant on the street in Manhattan’ leaves too much to the imagination for Stable Diffusion. Is the elephant approaching or moving away from the camera? What is the stance of its legs? Supplying a visual cue can significantly narrow down the possibilities, aligning the output more closely with your vision, as illustrated in the diagram below.
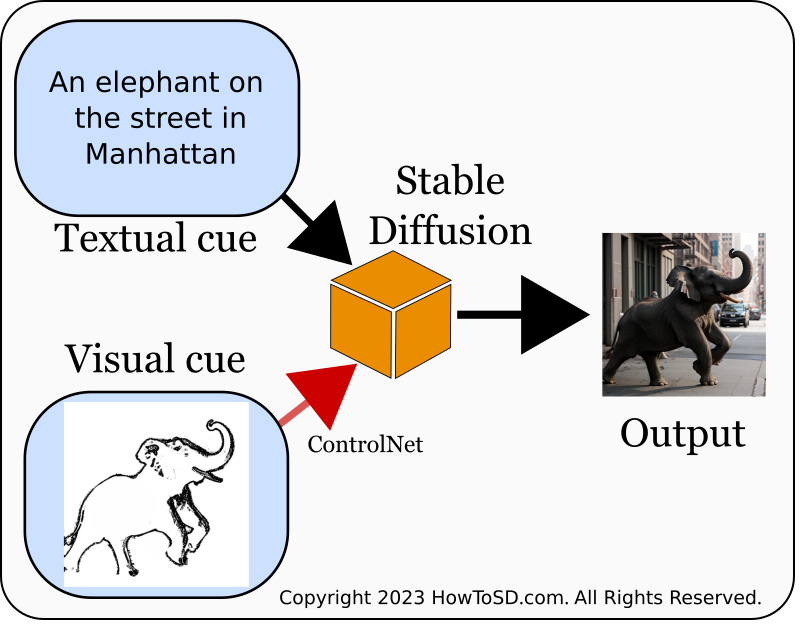
The screenshot below demonstrates how combining textual and visual cues successfully generated an image of an elephant in New York.
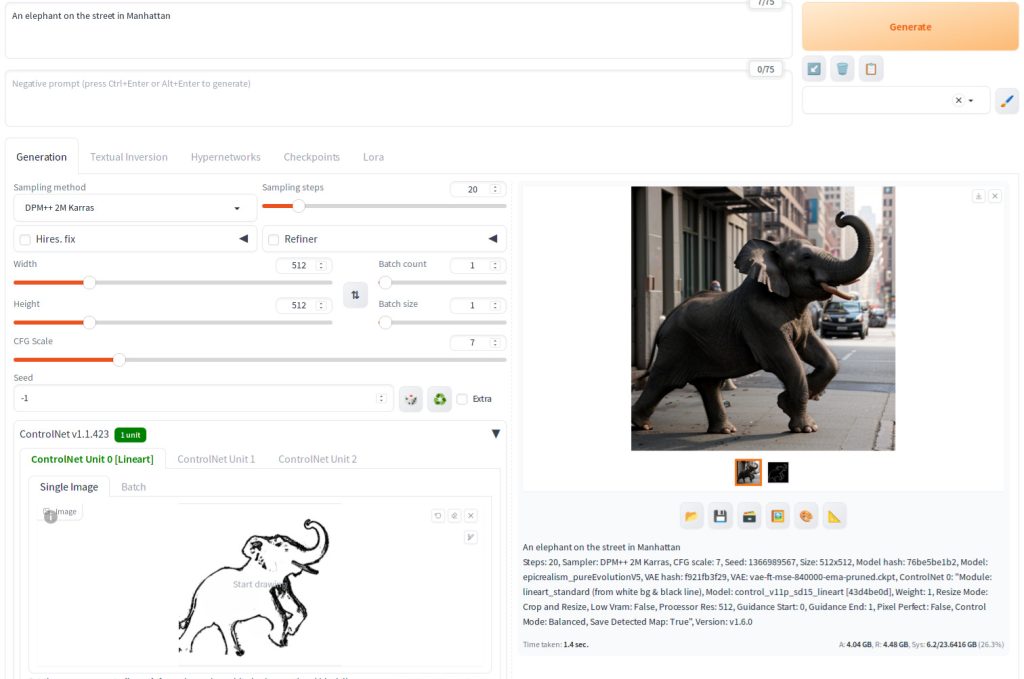
In this particular example, lineart serves as the visual cue. You can also use a regular image and extract the pose from the image and use as the cue for ControlNet as shown below.
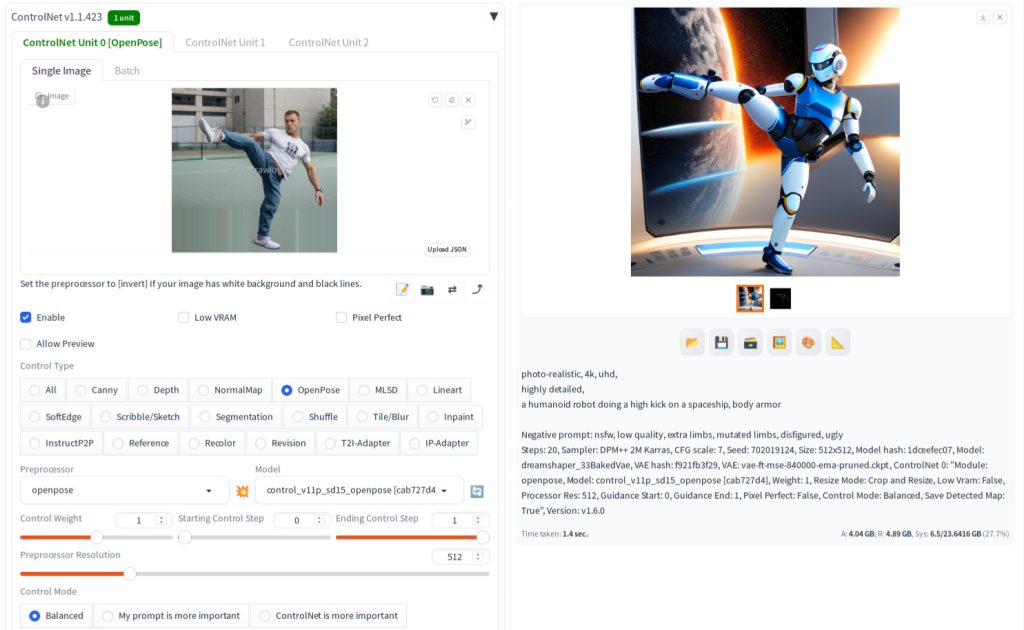
Let’s explore the workings of ControlNet, which comprises two main components. The first part is a preprocessor that transforms an image into a format suitable for the ControlNet model. This model then collaborates with Stable Diffusion to guide image generation. For instance, with the first lineart image, the preprocessor inverts it, changing black lines on a white background to white lines on a black background. In the case of the high-kick image, the subject’s pose is extracted using the OpenPose preprocessor, and this pose data is fed into the OpenPose ControlNet model. The following figure illustrates these transformations.

If you already possess an image that is directly compatible with a ControlNet model, you can bypass the preprocessing step. With this basic understanding of the problems ControlNet can solve and its high-level functionality, we’re ready to move on to setting it up. Our next tutorial guides you through the setup process.