
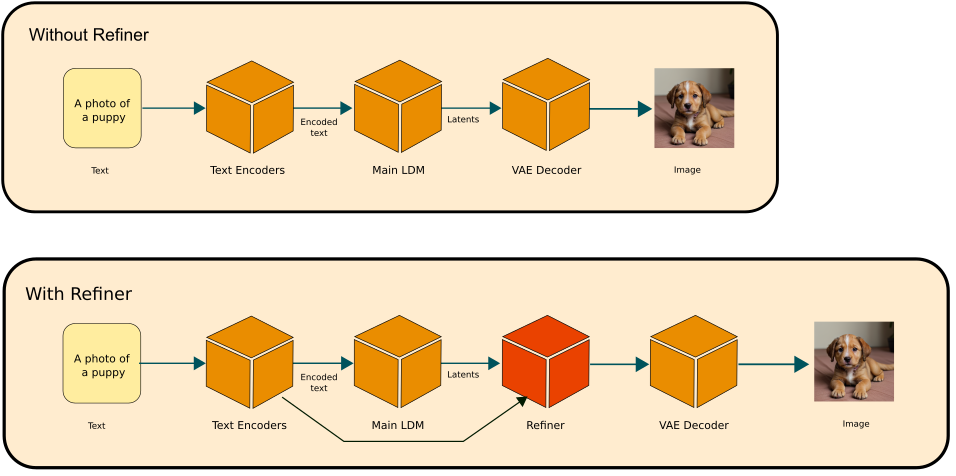
The Refiner is a component introduced in SDXL to enhance the quality of generated images. The diagram below illustrates the Refiner’s role in the SDXL framework [1]. In the absence of the Refiner, Fooocus employs the conventional image generation pathway established in SD 1.5. When the Refiner is incorporated, it processes the latents (the denoised image in latent space) produced by the main Latent Diffusion Model (LDM), performing denoising to produce a refined denoised image. This image is then decoded by a Variational Autoencoder (VAE) decoder to yield the final output image. For those of you who are familiar with hires-fix, Refiner is based on the exactly the same idea to enhance the quality of the image using img2img except that upscaling part is not included for the refiner flow. It’s important to note that while the Refiner improves image quality in the early SDXL models, the advancements in new SDXL models’ capabilities have reduced the necessity for a Refiner. Therefore, its inclusion should be considered based on the specific requirements and the version of the model in use.
Settings
Two main settings that you need to tweak are both available on the Model tab:
- Refiner
- Refiner Switch At
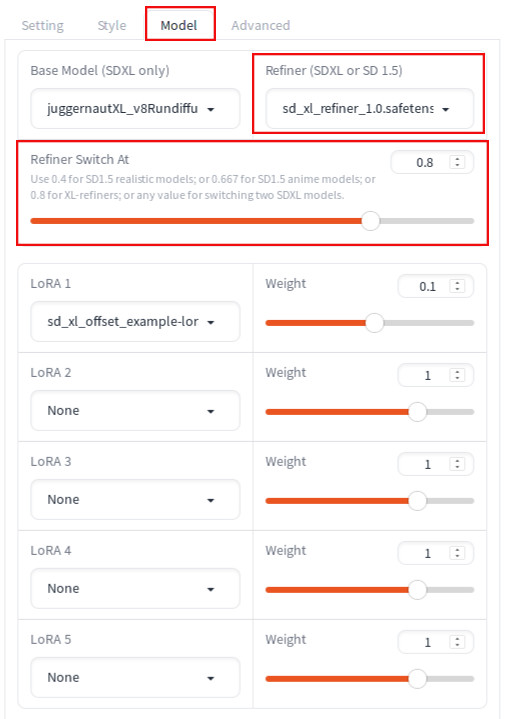
In addition, there is a Refiner swap method setting that is visible when Developer Debug Mode. By default, it is set to joint, which is what we use in this tutorial. Discussion of the Refiner swap method is outside the scope of this post. In the reference section [3] at the end of this post, you will find a link to the relevant part of the source code that shows how different Refiner swap methods are handled if you are interested in exploring more.
Refiner setting
You can specify any model including SD 1.5 or a non-refiner SDXL model in addition to a refiner model. For SD 1.5, see: How to use SD 1.5 model in Fooocus. Specifying a non-refiner model can add an interesting effect. For example, using animaPencilXL_v100.safetensors as a refiner while specifying juggernautXL_v8Rundiffusion.safetensors as the base model can make the image look anime-like. For the original use case to improve the image quality using a Refiner model, you will need to follow the below steps:
- Download the official Refiner model
sd_xl_refiner_1.0.safetensorsfrom https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/tree/main. - Move the model to
Fooocus/models/checkpoints. Now, you should see thesd_xl_refiner_1.0.safetensorsin the Refiner dropdown list and be able to select it.
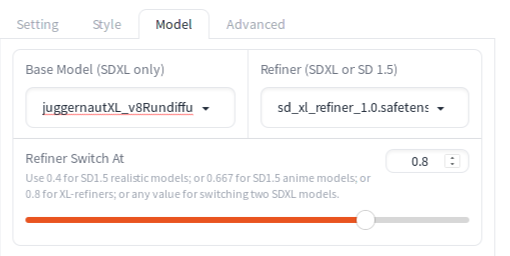
Refiner Switch At setting
You will specify a point when Fooocus switches from the base model to the refiner model during the denoising iterations. 0.8 is recommended for using the refiner model for SDXL. If the sampling steps are 30, then Fooocus switches to the refiner model after 24 steps (30 * 0.8 = 24). If you pay attention to the console while generating an image, you can see this switch in the progress bar.
Generation
Once you set these two parameters, you can press Generate to generate an image. Here are the example generation result with different Refiner Switch At values (shown below each image). The base model is juggernautXL_v8Rundiffusion.safetensors:





Generation parameters
Note: This is for Refiner Switch At = 0.8. Adjust this parameter if you want to try different values.
{
"Prompt": "Face of a beautiful 26-year-old woman, classy clothes",
"Negative Prompt": "",
"Fooocus V2 Expansion": "Face of a beautiful 26-year-old woman, classy clothes, open friendly, modern elegant, very detailed, intricate, cool, charming, magical, enchanted, background light, professional, sharp focus, determined, expressive, cute, dramatic, illuminated, pretty, attractive, depicted, deep royal, elite, colorful, guarded, extremely, amazing, slick, highly detail",
"Styles": "['Fooocus V2', 'Fooocus Enhance', 'Fooocus Sharp']",
"Performance": "Speed",
"Resolution": "(1152, 896)",
"Sharpness": 2,
"Guidance Scale": 4,
"ADM Guidance": "(1.5, 0.8, 0.3)",
"Base Model": "juggernautXL_v8Rundiffusion.safetensors",
"Refiner Model": "sd_xl_refiner_1.0.safetensors",
"Refiner Switch": 0.8,
"Sampler": "dpmpp_2m_sde_gpu",
"Scheduler": "karras",
"Seed": 1221057804251280948,
"LoRA 1": "sd_xl_offset_example-lora_1.0.safetensors : 0.1",
"Version": "v2.1.865"
}As you can see Refiner Switch at 0.8, 0.9 and no refiner images are virtually indistinguishable, making a case for the omission of a Refiner model.
Here are the example generation result for using sd_xl_base_1.0.safetensors as the base model with different Refiner Switch At values (shown below each image):





Generation parameters
Note: This is for Refiner Switch At = 0.8. Adjust this parameter if you want to try different values.
{
"Prompt": "Face of a beautiful 26-year-old woman, classy clothes",
"Negative Prompt": "",
"Fooocus V2 Expansion": "Face of a beautiful 26-year-old woman, classy clothes, open friendly, modern elegant, very detailed, intricate, cool, charming, magical, enchanted, background light, professional, sharp focus, determined, expressive, cute, dramatic, illuminated, pretty, attractive, depicted, deep royal, elite, colorful, guarded, extremely, amazing, slick, highly detail",
"Styles": "['Fooocus V2', 'Fooocus Enhance', 'Fooocus Sharp']",
"Performance": "Speed",
"Resolution": "(1152, 896)",
"Sharpness": 2,
"Guidance Scale": 4,
"ADM Guidance": "(1.5, 0.8, 0.3)",
"Base Model": "sd_xl_base_1.0.safetensors",
"Refiner Model": "sd_xl_refiner_1.0.safetensors",
"Refiner Switch": 0.8,
"Sampler": "dpmpp_2m_sde_gpu",
"Scheduler": "karras",
"Seed": 1221057804251280948,
"LoRA 1": "sd_xl_offset_example-lora_1.0.safetensors : 0.1",
"Version": "v2.1.865"
}Though the difference between switch-at 0.8 and no Refiner is not apparent, switch-at 0.5 definitely shows a different look. So you can try different switch-at values if you decide to use a Refiner.
References
[1] Dustin Podell et al. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis.
[2]Chenlin Meng et al. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
[3] lllyasviel. Fooocus. Retrieved from https://github.com/lllyasviel/Fooocus/blob/main/modules/default_pipeline.py#L360