
When creating images for a graphic novel, it’s essential to maintain consistency in the appearance of each character. Traditionally, achieving this uniformity has been a challenging task in Stable Diffusion. However, a recent technological advancement, known as FaceID, is making significant strides in addressing this challenge. This technology utilizes a single reference image to generate various images in different settings, maintaining the facial features from the reference as a base. Excitingly, this feature is now accessible in Automatic1111, offering ease of use. It’s important to note that while the generated faces will resemble the reference, they won’t be exact replicas. Nonetheless, you can expect a notable consistency in the faces produced. Let’s explore how this works.
Setting up
FaceID requires models and a Python package that are not in the main Automatic1111 package. There are two types of models. One is for SD 1.5 and the other is for SDXL. If you are only interested in using one type of a model, you can skip downloading the other type of models.
Downloading InsightFace Python package, FaceID models and LoRAs
You need to download:
- InsightFace Python package
- FaceID Models
- LoRAs
Refer to https://github.com/Mikubill/sd-webui-controlnet/discussions/2442 regarding where to download both FaceID models and LoRAs. This page and InsightFace’s README page (https://github.com/deepinsight/insightface/tree/master/python-package) contain information regarding how to install InsightFace. Note that you may also need to install the onnxruntime-gpu package. Refer to the InsightFace’s README page for further information.
Installing models and LoRAs
Once you downloaded the models & LoRAs, move them to the following directories:
FaceID models: Move 5 models that you downloaded to stable-diffusion-webui/extensions/sd-webui-controlnet/models:
- ip-adapter-faceid_sd15.bin
- ip-adapter-faceid-plus_sd15.bin
- ip-adapter-faceid-plusv2_sd15.bin
- ip-adapter-faceid_sdxl.bin
- ip-adapter-faceid-plusv2_sdxl.bin
LoRAs: Move 5 LoRAs that you downloaded to stable-diffusion-webui/models/Lora:
- ip-adapter-faceid_sd15_lora.safetensors
- ip-adapter-faceid-plus_sd15_lora.safetensors
- ip-adapter-faceid-plusv2_sd15_lora.safetensors
- ip-adapter-faceid_sdxl_lora.safetensors
- ip-adapter-faceid-plusv2_sdxl_lora.safetensors
Verify InsightFace installation
You can use the pip show command to check if the InsightFace package has been installed correctly in the virtualenv for Automatic1111. First activate the virtualenv, then type pip show as shown below:
stable-diffusion-webui $ source venv/bin/activate
(venv) stable-diffusion-webui $ pip show insightface
Name: insightface
Version: 0.7.3
Summary: InsightFace Python Library
Home-page: https://github.com/deepinsight/insightface
Author: InsightFace Contributors
Author-email: contact@insightface.ai
License: MIT
Location: <Installation dependent part of path removed ...>/stable-diffusion-webui/venv/lib/python3.10/site-packages
Requires: albumentations, cython, easydict, matplotlib, numpy, onnx, Pillow, prettytable, requests, scikit-image, scikit-learn, scipy, tqdmUpdating the ControlNet extension
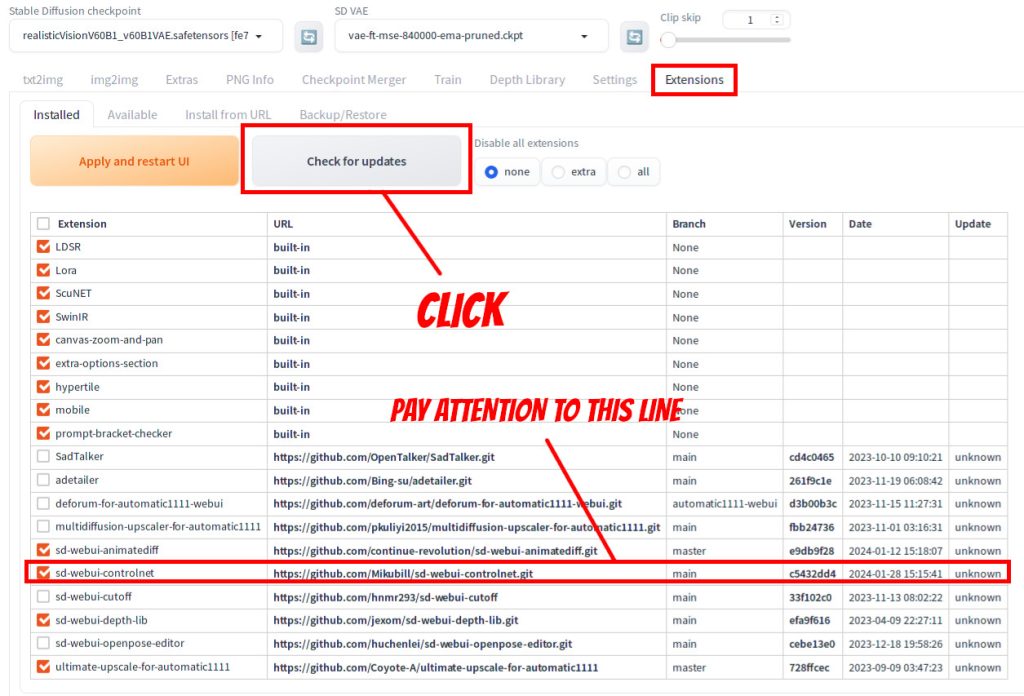
Start Automatic1111 and go to Extensions tab | Installed Tab. Click Check for Updates. If sd-webui-controlnet has a new version, it should indicate that. Apply the update and restart UI. Note that if you have an old version of Automatic1111 (e.g. before 1.6), most likely you also need to update Automatic1111 as well.
Using FaceID
We will be using below image as the reference for faces. This was generated in Stable Diffusion using epicrealism_pureEvolutionV5.

Steps
You have a choice of using a SD 1.5 model or an SDXL model to use FaceID. In this tutorial, we will be covering SD 1.5 and will be using the epicrealism_pureEvolutionV5 model. Note that steps for SDXL are the same except that you will need to use the SDXL version of the LoRA and the FaceID model. After you load the main model, enter the positive and negative prompts.
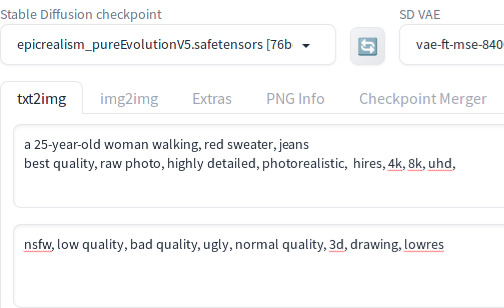
Then click the Lora tab, and enter ip-adapter-faceid in the search field. You should see all 5 LoRAs for FaceID. Click lora:ip-adapter-faceid-plusv2_sd15_lora.
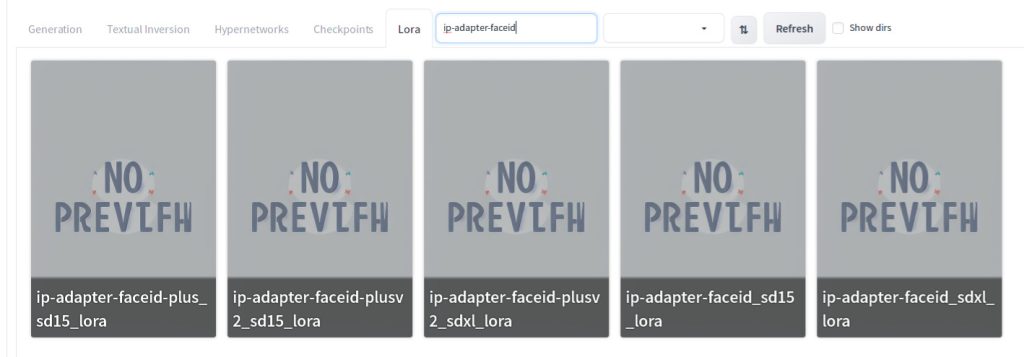
You should see <lora:ip-adapter-faceid-plusv2_sd15_lora:1> is appended to the positive prompt. Change the value to 0.5 so that LoRA tag should say <lora:ip-adapter-faceid-plusv2_sd15_lora:0.5>
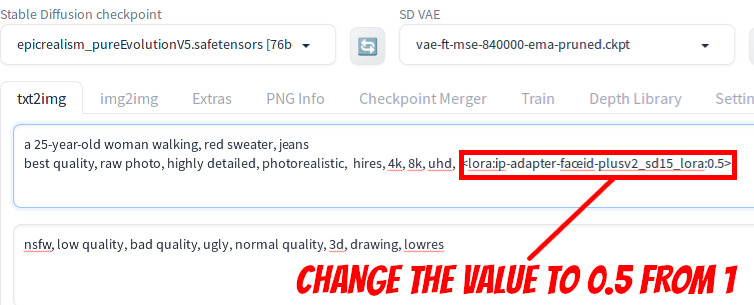
Now scroll down to the ControlNet section.
On ControlNet Unit 0 tab,
- Drag the cropped face reference image to the canvas
- Select
Enable - Select
Low VRAM - Select
Pixel Perfect - In
Control Type,selectIP-Adapter - In
Preprocessor,selectip-adapter_face_id_plus - In
Model,selectip-adapter-faceid-plusv2_sd15
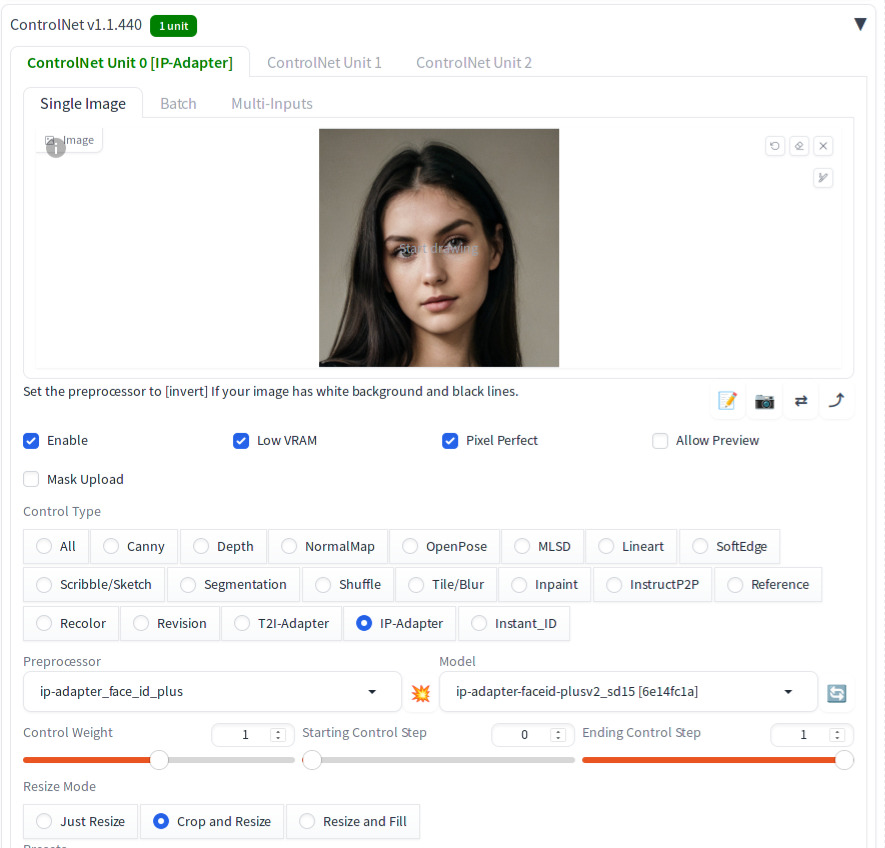
Note that LoRA name and the model name have to match exactly. For preprocessor, use below mapping [1]:
For ip-adapter_face_id preprocessor
- ip-adapter-faceid_sd15
- ip-adapter-faceid_sdxl
For ip-adapter_face_id_plus preprocessor
- ip-adapter-faceid-plus_sd15
- ip-adapter-faceid-plusv2_sd15
- ip-adapter-faceid-plusv2_sdxl
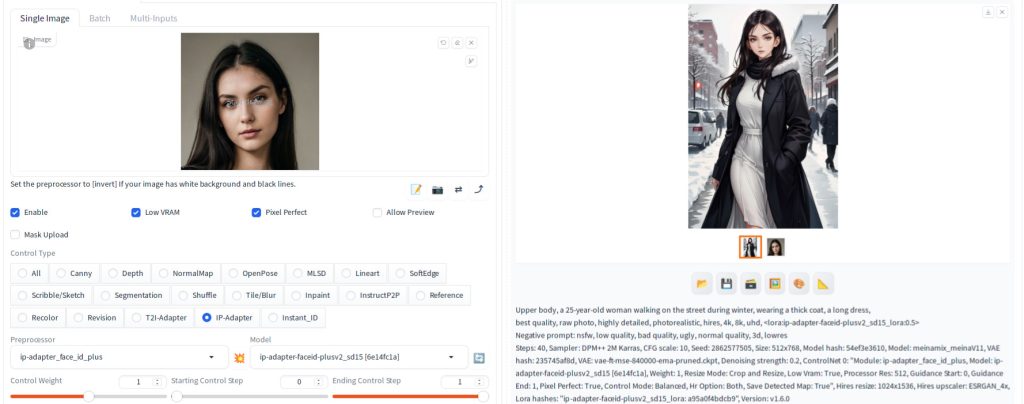
Now press Generate. Here are unedited 4 sample images:
Common Generation parameters (except positive prompt)
Negative prompt: nsfw, low quality, bad quality, ugly, normal quality, 3d, drawing, lowres
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 1524504649, Size: 512x768, Model hash: 76be5be1b2, Model: epicrealism_pureEvolutionV5, VAE hash: 235745af8d, VAE: vae-ft-mse-840000-ema-pruned.ckpt, ControlNet 0: "Module: ip-adapter_face_id_plus, Model: ip-adapter-faceid-plusv2_sd15 [6e14fc1a], Weight: 1, Resize Mode: Crop and Resize, Low Vram: True, Processor Res: 512, Guidance Start: 0, Guidance End: 1, Pixel Perfect: True, Control Mode: Balanced, Hr Option: Both, Save Detected Map: True", Lora hashes: "ip-adapter-faceid-plusv2_sd15_lora: a95a0f4bdcb9"
a 25-year-old woman walking, red sweater, jeans
best quality, raw photo, highly detailed, photorealistic, hires, 4k, 8k, uhd, <lora:ip-adapter-faceid-plusv2_sd15_lora:0.5>
a 25-year-old woman reading a book in the library, wearing dress shirt, trousers,
best quality, raw photo, highly detailed, photorealistic, hires, 4k, 8k, uhd, <lora:ip-adapter-faceid-plusv2_sd15_lora:0.5>
a 25-year-old woman working in a coffee shop, wearing t-shirt, an apron, jeans,
best quality, raw photo, highly detailed, photorealistic, hires, 4k, 8k, uhd, <lora:ip-adapter-faceid-plusv2_sd15_lora:0.5>
Upper body, a 25-year-old woman walking on the street during winter, wearing a thick coat, a long dress,
best quality, raw photo, highly detailed, photorealistic, hires, 4k, 8k, uhd, <lora:ip-adapter-faceid-plusv2_sd15_lora:0.5>As you observed, the generated images feature faces that are clearly influenced by the source face. Additionally, you’ll notice a fair amount of similarity among generated faces, demonstrating the effectiveness of the technology in maintaining a consistent character appearance.
Generating anime images
Perhaps one of the most useful applications will be the creation of consistent characters using this technique. Below 4 images are generation results using the same cropped reference photo shown earlier but using an anime model (meinamix_meinaV11). Note face consistency is kept among the different images.

Set up
Generation parameters (prompt is for the first image)
a 25-year-old woman walking, red sweater, trousers,
best quality, raw photo, highly detailed, photorealistic, hires, 4k, 8k, uhd, <lora:ip-adapter-faceid-plusv2_sd15_lora:0.5>
Negative prompt: nsfw, low quality, bad quality, ugly, normal quality, 3d, lowres
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 10, Seed: 2862577505, Size: 512x768, Model hash: 54ef3e3610, Model: meinamix_meinaV11, VAE hash: 235745af8d, VAE: vae-ft-mse-840000-ema-pruned.ckpt, Denoising strength: 0.2, ControlNet 0: "Module: ip-adapter_face_id_plus, Model: ip-adapter-faceid-plusv2_sd15 [6e14fc1a], Weight: 1, Resize Mode: Crop and Resize, Low Vram: True, Processor Res: 512, Guidance Start: 0, Guidance End: 1, Pixel Perfect: True, Control Mode: Balanced, Hr Option: Both, Save Detected Map: True", Hires resize: 1024x1536, Hires upscaler: ESRGAN_4x, Lora hashes: "ip-adapter-faceid-plusv2_sd15_lora: a95a0f4bdcb9"What if we use an uncropped image as a control input? Let’s try. Here is the source image:

Below are the results:

As you can see, face consistency is still kept. This is most likely due to face embedding of a detected face being used as one of the inputs internally [3].
You can easily create a different character by using a different photo-like image. Below is an example of the uncropped reference image and sample generation using the same anime model:


Troubleshooting
If you cannot see any resemblance, here are some items to check.
- Verify that you are using a cropped face image, but do not crop too tight around the face as InsightFace may not be able to detect the face. If the generated face does not resemble the source face at all, check the console output and see if you see this error:
- raise Exception(f”Insightface: No face found in image {i}.”)”
- NameError: name ‘i’ is not defined
- Verify that you did not forget to add LoRA to the prompt that matches the model.
- Try different models.
- Try tweaking the LoRA weight. As a guideline, [1] recommends 0.5 – 0.7 but you are free to try values outside this range.
References
[1] huchenlei. [1.1.428] IP-Adapter FaceID #2442. Retrieved from https://github.com/Mikubill/sd-webui-controlnet/discussions/2442
[2] h94. IP-Adapter-FaceID. Retrieved from https://huggingface.co/h94/IP-Adapter-FaceID
[3] sd-webui-controlnet/scripts/processor.py. Retrieved https://github.com/Mikubill/sd-webui-controlnet/blob/main/scripts/processor.py#L829