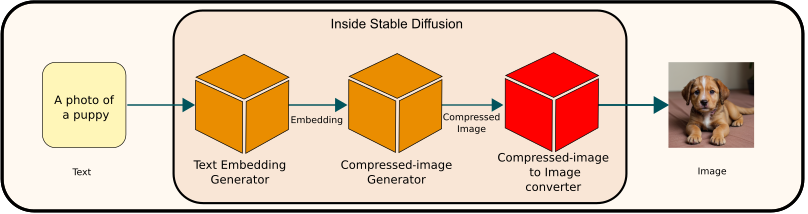
Overview
The compressed image to image conversion module plays a crucial role in transforming the output from the compressed image generation module (latent diffusion) into the final high-resolution image. This process utilizes a decoder model from a Variational Autoencoder (VAE) framework. Specifically, it takes a compressed image of dimensions 64 x 64 x 4 and reconstructs it into a final image measuring 512 pixels in height and width, in RGB format.
What is Variational Autoencoder?
A Variational Autoencoder is a sophisticated model in the field of deep learning, primarily used for generating compressed representations of data in a latent space. It consists of two main components: an encoder and a decoder. The encoder maps the input image to a lower-dimensional latent space, effectively compressing the data. The decoder then takes this compressed representation and reconstructs the original image from it, as illustrated in the figure below. This process is key in applications like image generation and enhancement, where managing data in a compressed form is advantageous for efficiency and performance.
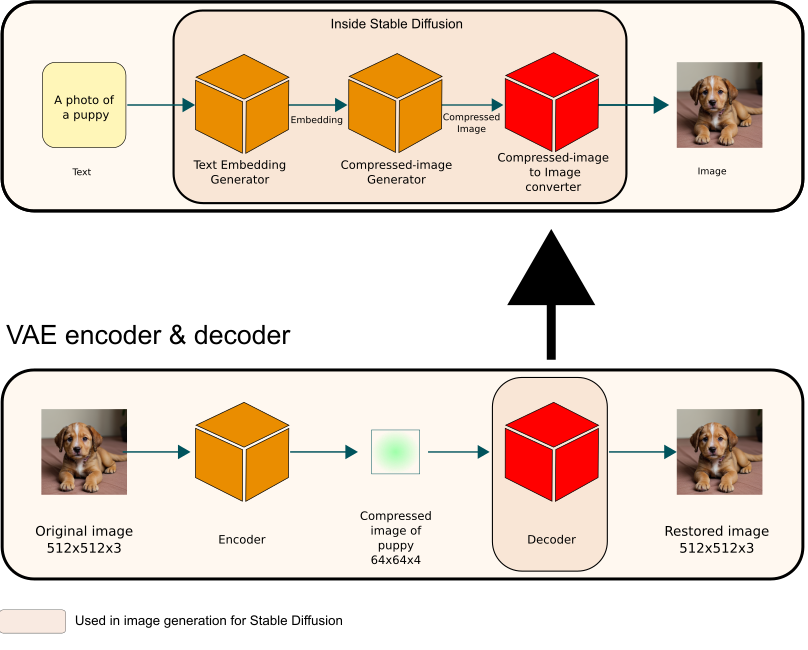
You might be familiar with the term ‘Autoencoder’. The key difference between a standard autoencoder and a Variational Autoencoder (VAE) lies in how they handle the latent space representation of the input data. Unlike a regular autoencoder that aims to map the input image to a specific point in the latent space, a VAE is designed to learn the parameters of a probability distribution representing this space. It then samples from this distribution to generate new data. This characteristic enables VAEs to be effectively used in generating new images, making them more versatile compared to standard autoencoders.
In the context of Stable Diffusion, the VAE model functions independently from the latent diffusion model. Within this setup, only the decoder component of the VAE is utilized for converting text into images. This specialized use of the decoder allows for the efficient transformation of compressed, latent representations into detailed and coherent final images.
Code references
For readers interested in exploring the technical details of how this is implemented in Stable Diffusion, you can visit the official GitHub repository of the Stable Diffusion developers. The relevant model is defined within their codebase, which you can find at:
- The main autoencoder model: https://github.com/CompVis/stable-diffusion/blob/main/ldm/models/autoencoder.py#L285
- The Decoder model: https://github.com/CompVis/stable-diffusion/blob/main/ldm/modules/diffusionmodules/model.py#L462
These links will take you directly to the specific sections of the code where the models are defined, offering an in-depth look at the architecture and functionality of VAE in the Stable Diffusion system.